
type
status
date
slug
summary
tags
category
icon
password
MySQL索引(一) — 理解索引
1.索引是什么
想象一下这样的场景:
当你试图在字典中寻找一个字的时候,你是会选择一页一页的区翻找呢?还是尝试从字典所给出的目录中去寻找呢?
很显然,正常情况下都会在字典给出的目录中找到对应的页码,在翻到对应的页。由此可见,书中的目录,就是充当索引的角色,通过空间换时间的思想,来帮助我们快速找到所需内容。
所以,索引是提升查询速度的一种数据结构。
而索引之所以能够提升查询速度,主要原因是它在插入时对数据进行了排序。
2.索引的结构(B+ 树)
B+ 树是数据库系统中最常见的一种索引数据结构,基本上所有的关系型数据库都会支持它。
而数据库热衷于支持 B+ 树索引的主要原因,便是因为它是目前为止最有效率的数据结构。对于与它类似的数据结构,例如二叉树,红黑树,甚至于哈希,跳表(SkipList),在海量数据基于磁盘存储效率方面都远不如 B+ 树索引高效。
B+ 树的定义
B+ 树是一种多叉树,一棵 m 阶的 B+ 树定义如下:
- 每个节点最多有 m 个子女。
- 除根节点外,每个节点至少有
[m/2]个子女,根节点至少有两个子女。
- 有 k 个子女的节点必有 k 个关键字。
关键字可以直观理解为就是索引全部列的值
B+ 树的特征
B+ 树还有两个特征
- 叶子存放了数据,而非叶子节点只是存放了关键字。
- 叶子节点被链表串联起来了。
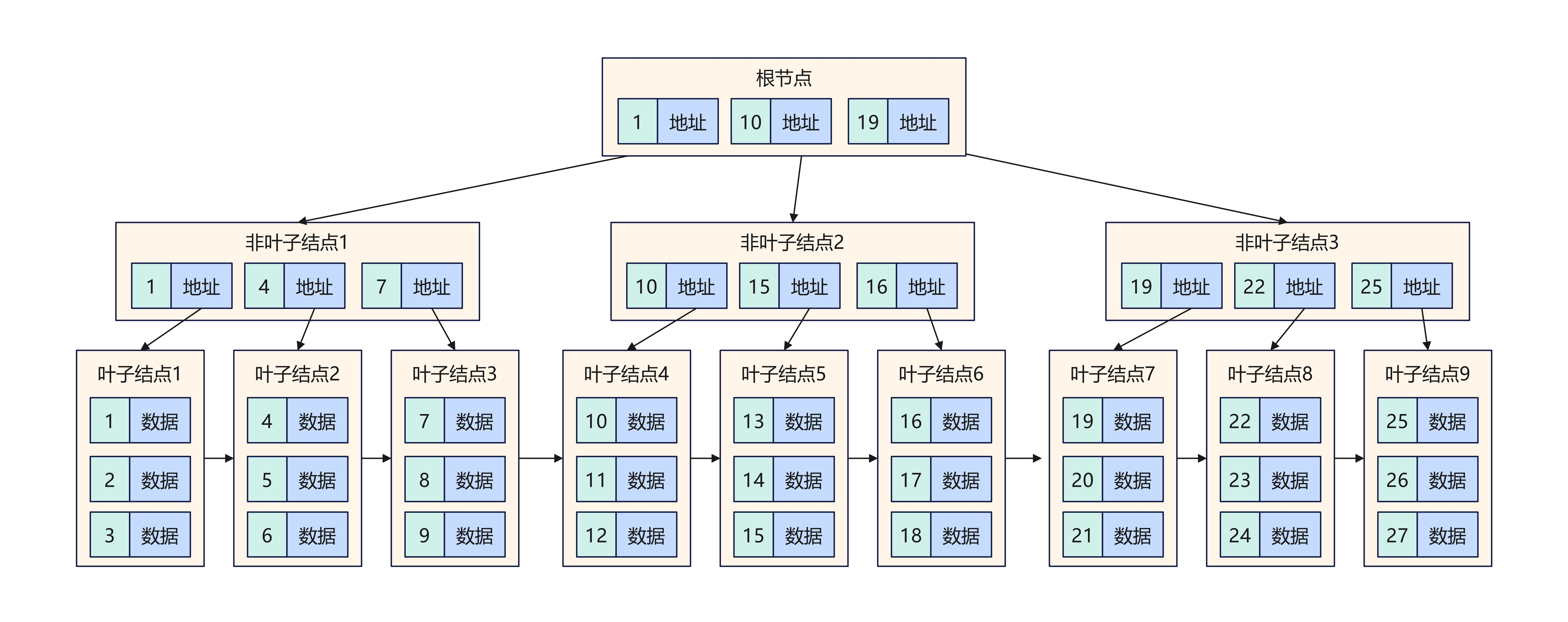
基于 B+ 树的两个特征和定义,可以看出 B+ 树的结构更偏向于矮胖,也就是对于相同的数据量,可以更快的找到相关数据。
B+ 树的存储效率
而在 MySQL 中,每次读取数据并不是一行行读取的,而是以页作为单位,将这一页读入内存中,而默认每个页的大小是 16KB。
那么我们可以假设场景,来看看 B+ 树的存储效率。
假设当前表为 user 表,所用索引树是主键索引 id ,所使用类型为 BIGINT,占用 8 字节大小,加上 MySQL InnoDB 引擎指针占用的 6 字节:
非叶子结点能最多存放以下多个键值对 = 16K / 键值对大小(8+6) ≈ 1100
而假设表中每条记录的大小为 500 字节,则:
叶子节点能存放的最多记录为 = 16K / 每条记录大小 ≈ 32
综上,假如 B+ 树高度为 n,最多能存放的记录数为:
总记录数 = 1100(根节点) * 1100(第2层的中间节点) …… * 1100(第 n - 1 层的中间节点) * 32*
不过,在真实环境中,每个页其实利用率并没有这么高,还会存在一些碎片的情况,我们假设每个页的使用率为60%,则:
B+ 树高度 | 每个非叶子结点存放的键值对 | 叶子结点存放的总记录数 |
1 | / | 19 |
2 | 660 | 12540 |
3 | 660 | 8276400 |
4 | 660 | 5462424000 |
从表格中可以看出,哪怕对于 54 亿的数据量,也只需要 4 次 I/O,大概为 0.0004 秒,就可以找到需要的数据。
B+ 树的优势
并且,B+ 树用于数据库索引还有三大优势:
- B+ 树的高度和二叉树之类的比起来更低,树的高度代表了查询的耗时,所以查询性能更好。
- B+ 树的叶子节点都被串联起来了,适合范围查询。
- B+ 树的非叶子节点没有存放数据,所以适合放入内存中。
第三点是常被忽略的优势,因为我们在讨论使用索引提高查询性能的时候,一个默认的前提就是索引本身会全部装进内存中,只有真实的数据行会放在磁盘上。
3.索引的分类
我们可以按照四个角度来分类索引。
- 按「数据结构」分类:B+ 树索引、Hash 索引、Full-text 索引。
- 按「物理存储」分类:聚簇索引(主键索引)、非聚簇索引(二级索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
按数据结构分类
从数据结构的角度来看,MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
按物理存储分类
从物理存储的角度来看,索引分为聚簇索引(主键索引)、非聚簇索引(二级索引)。
它们之间也很好区分:如果索引叶子节点存储的是数据行,那么它就是聚簇索引,否则就是非聚簇索引。
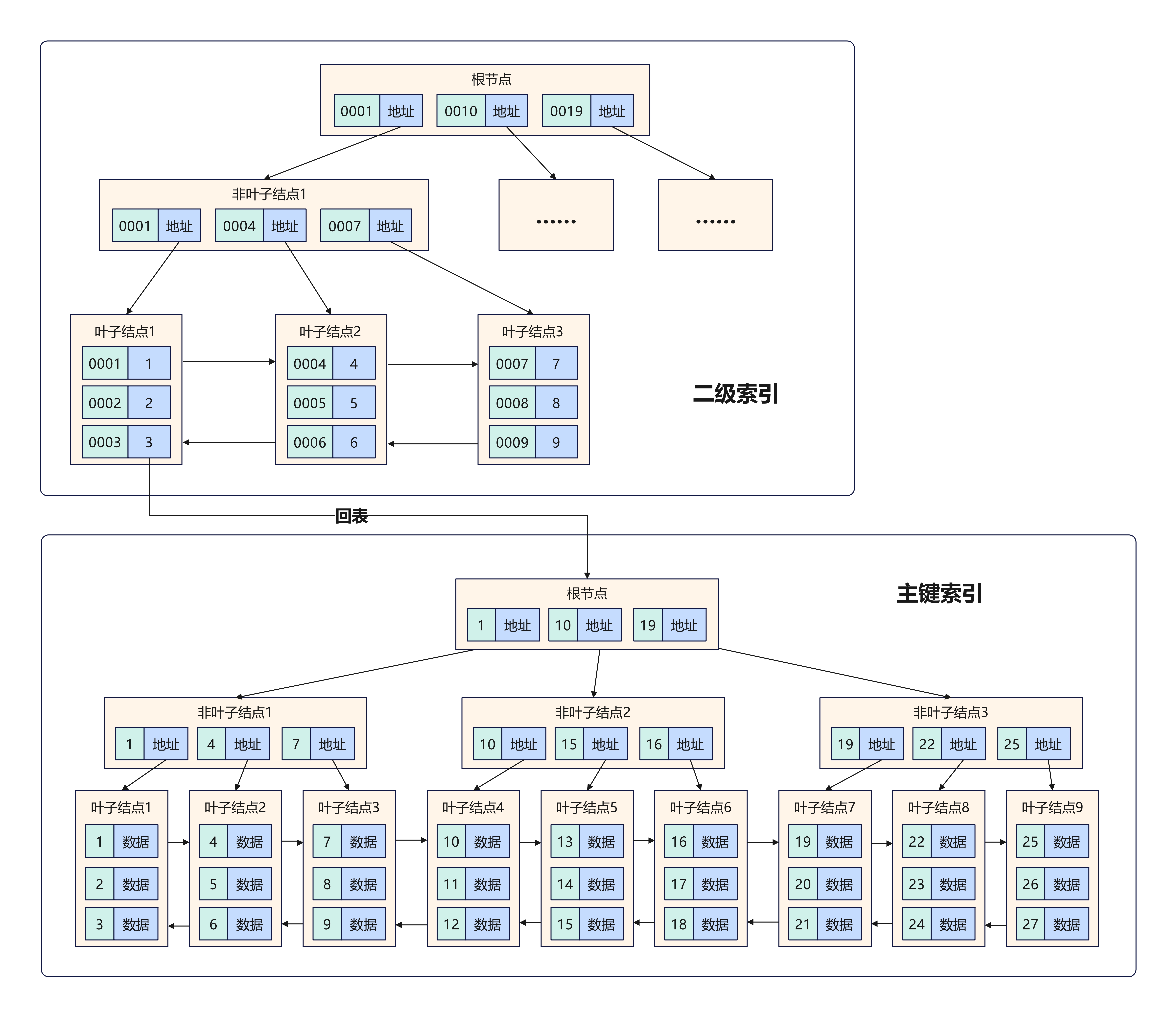
简单来说,某个数据表本身你就可以看作是一棵使用主键搭建起来 B+ 树,这棵树的叶子节点放着表的所有行。而其他索引也是 B+ 树,不同的是它们的叶子节点存放的是主键。
因此,回表操作就是当你查询表时,如果使用了索引,那么数据库就会先在索引里找到主键,然后再根据主键到聚簇索引中查找,最终找到数据。
很显然,回表操作的性能极差,因为你需要两倍的磁盘 IO 时间才能找到对应的数据,所以我们应当尽量避免回表操作。
如果当前索引包含了所有所需要查询的列,那么此时就无需回表查找,这个情况被称为 “索引覆盖”
按字段特性分类
从字段特性的角度来看,索引分为主键索引、唯一索引、普通索引、前缀索引。
主键索引
主键索引就是建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
唯一索引
唯一索引建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
普通索引
普通索引就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
唯一索引vs普通索引
通过观察唯一索引和普通索引的定义,我们似乎发现两者之间只在是否允许索引列的值唯不唯一上有区别。那么,当我们的业务要求某个字段需要唯一时,我们应该直接对它建立唯一索引吗?
实际上答案是否定的,详细解析可以看《MySQL实战45讲》中的 09-普通索引和唯一索引,应该怎么选择?,这里只做简单解析:
查询操作
- 唯一索引由于保证了数据的唯一性,只需要找到唯一一个对应的数据即可停止检索,而普通索引则需要继续往下寻找直到找到第一个不符合的数据为止(或者查询完所有数据)。
- 但实际上这两者之间的差距十分之小,因为 MySQL 读入数据是以 “页” 的单位来读取的,很少会出现跨页查找的情况。
更新操作
如果要在这张表中插入一个新记录 (4, 400) 的话,InnoDB 的处理流程是怎样的
- 假如这个记录要更新的目标页在内存中
- 对于唯一索引来说,找到 3 和 5 之间的位置,判断到没有冲突,插入这个值,语句执行结束。
- 对于普通索引来说,找到 3 和 5 之间的位置,插入这个值,语句执行结束。
很显然这种情况下,两者差距并不大
- 这个记录要更新的目标页不在内存中
- 对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束。
- 对于普通索引来说,则是将更新记录在 change buffer,语句执行就结束了。
而将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer 因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。
change buffer:当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB 会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
综上,由于唯一索引无法使用 change buffer,会导致性能差于非唯一索引,所以除非业务要求,否则尽可能使用普通索引。
前缀索引
前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
按字段个数分类
从字段个数的角度来看,索引分为单列索引、联合索引(复合索引)。
- 建立在单列上的索引称为单列索引,比如主键索引。
- 建立在多列上的索引称为联合索引。
联合索引
通过将多个字段组合成一个索引,该索引就被称为联合索引。
例如将 user 表中的 id 和 price 字段组合成联合索引
idx_id_price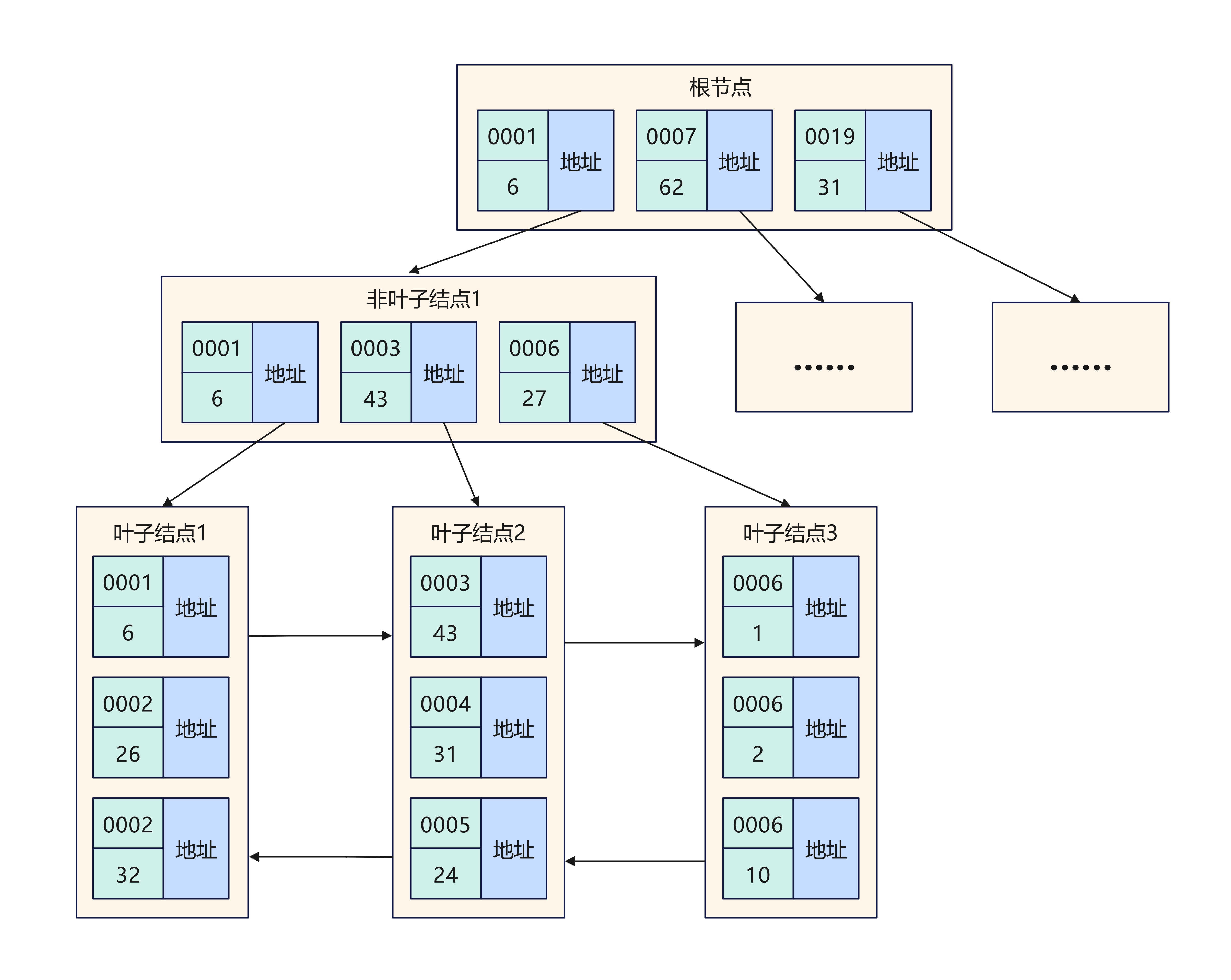
由图可见,联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。当在联合索引查询数据时,先按 id 字段比较,在 id 相同的情况下再按 price 字段比较。
因此,在使用联合索引时,存在最左匹配原则,即按照最左优先的方式进行索引的匹配。
最左匹配原则的失效情况
假设在 pinyin 表上创建了一个组合索引 idx_A_B_C
id | A(声母) | B(韵母) | C(声调) |
1 | b | a | 1 |
2 | b (同↑) | ang | 2 |
3 | b (同↑) | ang (同↑) | 3 |
4 | b (同↑) | ong | 2 |
5 | ch | a | 4 |
6 | ch (同↑) | ao | 1 |
7 | ch (同↑) | ao (同↑) | 4 |
8 | g | ang | 3 |
由此可见,
- A 列是绝对有序的
- 在 A 确定的情况下,B 是有序的
- 在 A 和 B 都确定的情况下,C 是有序的
也就是说,B 和 C 是全局无序的,但局部是相对有序的。
那么反过来说:
- 如果 A 列的值不确定,那么 B 和 C 都是无序的。例如当 A 取值可能为 b 或者 ch 的时候,B 的取值可能是 (a, ang, ong, ao)。
- 如果 A 的值确定,但是 B 的值不确定,那么 C 是无序的。例如当 A 为 b 而 B 可能是 a 或者 ang 的时候,C 的值可能是 (1, 2, 3)。
那么也就是只有以下的查询条件才能使用配合索引:
- WHERE A = 'b'
- WHERE B = 'a' AND A = 'b'
- WHERE A = 'b' and B = 'a' AND c = 1
由于优化器的存在,第二条中顺序会自动优化,所以 A 字段在 SQL 语句中的实际位置并不重要
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。
就拿上面的 pinyin 表举例,面对下面的 SQL 语句时
由于联合索引是先按照 A 字段的值进行排序的,所以符合 A > 'b' 的二级索引记录肯定相邻,那么就可以在进行索引扫描的同时,定位到符合 A >'b' 的第一条记录,然后沿着记录所在连表往后找到不符合 A > 'b' 的条件位置,所以 A 字段是可以走联合索引进行查询的。
但是在符合 A > 'b' 条件的二级索引记录的范围里,B 字段的值是无序的。因此,我们无法根据 B = 'ao' 来使用联合索引进行查询。
但对于 >=、<=、BETWEEN、LIKE 前缀匹配的范围查询,并不会停止匹配。
例如下面的 SQL 语句
由于联合索引(二级索引)是先按照 A 字段的值排序的,所以前缀为 ‘ch’ 的 A 字段的二级索引记录都是相邻的, 于是在进行索引扫描的时候,可以定位到符合前缀为 ‘ch’ 的 A 字段的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录的 A 前缀不为 ‘ch’ 为止。
虽然在符合前缀为 ‘ch’ 的 A 字段的二级索引记录的范围里,B 字段的值是 “无序” 的,但是对于符合 A = 'ch' 的二级索引记录的范围里,B 字段的值是 "有序" 的。
所以,当二级索引记录的 A 字段值为 'ch' 时,可以通过 B = 'ao' 来减少需要扫描的二级索引记录范围,也就意味着 B 字段在此时也能运用到联合索引。
也就是说,从符合 A = 'ch' AND B = 'ao'’ 条件的第一条记录时开始扫描,而不需要从第一个 A 为 ‘ch’ 的记录开始扫描。
参考资料:
- 《MySQL实战45讲》
- 作者:Tuwilt
- 链接:https:/blog.tuwilt.top/article/4454d1b1-28ef-480e-91b1-7d8dd39b4005
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。